
In archives or repositories, access rights regulate who has access to data and to what extent, particularly for reuse. Typically, access is categorized as follows:
|
|---|
Analog research materials are artifacts or objects of ritual or everyday use. They are created or collected during ethnographic fieldwork and may include items such as photographs, notes, books, audio tapes, drawings, or sculptures. To make these materials reusable online, they must first be digitized and provided with appropriate metadata, allowing them to be made accessible in a repository, for example (Forschungsdaten.info, 2023). The organization OpenAIRE provides guidelines for the secure handling of analog, non-digital research data1see: https://www.openaire.eu/non-digital-data-guide. | |
|---|---|
| Related glossary entries | |
According to the German Federal Data Protection Act (BDSG § 3, para. 6 in the version valid until May 24, 2018), anonymization is understood to mean all measures for modifying personal data in such a way “that the individual details about personal or factual circumstances can no longer be assigned to an identified or identifiable natural person, or can only be assigned to an identified or identifiable natural person with a disproportionate investment of time, cost and labor.” Anonymized data is therefore data that does not (or no longer) provide any information about the person concerned. As such, it is not subject to data protection or the General Data Protection Regulation (GDPR). | |
|---|---|
| Related glossary entries | |
Archiving refers to the storage and accessibility of research data and materials. The aim of archiving is to enable long-term access to research data. On one hand, archived research data can be reused by third parties as secondary data for their own research questions. On the other hand, archiving ensures that research processes remain verifiable and transparent. There is also long-term archiving (LTA), which aims to ensure the usability of data over an indefinite period of time. LTA focuses on preserving the authenticity, integrity, accessibility, and comprehensibility of data. In many disciplines, a standard retention period of at least ten years has been established for research data. Since this period may be impacted by technological changes, regular review of the data is necessary to ensure its preservation and usability. | |
|---|---|
| Related glossary entries | |
Authority data provide standardized records and unique identifiers in the form of specific numbers that distinctly describe and categorize individuals, works, institutions, research funders, entities, or keywords. This standardization eliminates incorrect or duplicate assignments. Authority data is particularly useful in catalogs and databases, where it facilitates easy retrieval of information about specific entities and supports digital networking and discoverability across projects. In Germany, the “Integrated Authority File” (GND) by the German National Library is the central authority filei2 see: https://www.dnb.de/DE/Professionell/Standardisierung/GND/gnd_node.html. | |
|---|---|
| Related glossary entries | |
The term backup means data protection or data recovery and refers to the copying of data as a precaution in the event that data is lost, e.g. due to hard drive damage or accidental deletion. The data can be restored with a backup. For this purpose, the data record is additionally saved on another data carrier (backup copy) and stored offline or online. | |
|---|---|
| Related glossary entries | |
The CARE principles were established by the Global Indigenous Data Alliance (GIDA) in 2019. They complement the FAIR principles and are used as a tool to focus more strongly on research contexts and their historical embeddedness, as well as on power asymmetries in the field. The acronym stands for Collective Benefit (common good), Authority to Control (control of research participants over their own representation), Responsibility (responsibility on the part of researchers) and Ethics (consideration of ethical aspects). The CARE principles are intended to emphasize and take into account the fair, respectful and ethical treatment of research participants and the data generated from research with regard to data sharing. The CARE principles are therefore relevant in all phases of the research data life cycle and research data management. | |
|---|---|
| Related glossary entries | |
The term census (from Latin census) refers to population censuses, i.e., comprehensive surveys of a country’s population. Over 2,000 years ago, similar censuses were conducted every five years in the Roman Empire to gather information about population structure and wealth distribution. In 2022, Germany conducted a register-based census (i.e., relying on official registry data), supplemented by a sample survey and a building and housing survey. | |
|---|---|
| Related glossary entries | |
A controlled vocabulary consists of defined terms and rules organized in word lists or structured thesauri. It serves as a type of lexicon or encyclopedia for discipline-specific definitions, aiming to promote consistent scientific practice and make research interoperable and intersubjectively understandable. In the social sciences, the „European Language Social Science Thesaurus“ (ELSST) is particularly relevant3 siehe: https://elsst.cessda.eu. |
|---|
The German Copyright Act (UrhG) protects certain intellectual creations (works) and services. Works include literary works, photographic, film and musical works, as well as scientific or technical representations such as drawings, plans, maps, sketches, tables and plastic representations (§ 2 UrhG). The artistic, scientific achievements of persons or the investment made, on the other hand, are considered to be services worthy of protection (ancillary copyright). | |
|---|---|
| Related glossary entries | |
Creative Commons licenses are pre-formulated license agreements created by the non-profit organization Creative Commons, allowing copyright holders to grant public usage rights to their creative works. Once a work under a CC license is used by third parties according to the terms of the license, a contract is established (TUM, 2023, p. 5). Due to the standardized, modular structure of existing licenses, they are easy to understand even without legal expertise, and over 2 billion CC-licensed works are widely distributed, supporting a culture of sharing and reuse. They are both human- and machine-readable (Creative Commons, 2023a; 2023b). Each modular element sets a condition for reuse, visualized by symbols and highly recognizable, allowing users to quickly understand what needs to be observed when reusing the work.The worldwide license agreements are composed of these elements: ELEMENTS
These elements make up the six licenses available worldwide (Creative Commons, 2023b). | |
|---|---|
| Related glossary entries | |
In scientific research processes, research data refers to all information collected both analog and digital. In social and cultural anthropology, research data is mostly, though not exclusively, gathered through stationary fieldwork and is methodologically characterized by participant observation. This means that data is purposefully generated through social interactions, observation, and interviews, and does not exist independently of the personal and affective interactions between researchers and participants. Therefore, in ethnographic fieldwork, one cannot speak of collecting pre-existing raw data; rather, data is processually created during research and must be understood as constructed. This distinguishes ethnographic research data from other sources and materials, such as newspaper reports, statistics, or historical documents, which exist independently of the ethnographer’s intervention and can be consulted and compiled for information purposes only. | |
|---|---|
| Related glossary entries | |
Research data not only form the basis of scientific publications by researchers but are also often made accessible to others. This requires that research data be documented in a clear and understandable way. This becomes essential if data publication is intended. Metadata – structured information about other data -plays a central role in finding, searching, and using research data. Various scientific communities have established metadata standards, which are conventions for describing and documenting research data through metadata. Appropriate documentation is part of any good scientific practice. | |
|---|---|
| Related glossary entries | |
Data journals, similar to traditional scientific journals, provide a platform for publishing research data through a peer-review process. Data journals are published by publishers and generally involve costs for readers or authors. |
|---|
A data management plan (DMP) describes and documents the handling of research data and materials during and after the project period. The DMP specifies how data and materials are generated, processed, stored, organized, published, archived, and, if applicable, shared. Additionally, it outlines responsibilities and rights. As a „living document“ (a dynamic document that is continuously revised and updated), the DMP is regularly reviewed and adjusted as needed throughout the course of the project. |
|---|
Data protection includes measures against the unlawful collection, storage, sharing, and reuse of personal data. It is based on the right of individuals to self-determination regarding the handling of their data and is anchored in the General Data Protection Regulation (GDPR), the Federal Data Protection Act (Bundesdatenschutzgesetz), and the corresponding laws of the federal states. A violation of data protection regulations can lead to criminal consequences. | |
|---|---|
| Related glossary entries | |
The Digital transformation is rapidly expanding the variety of methods and processes used to generate, process and disseminate data. As more and more decisions are based on digital data, questions regarding their origin and quality become increasingly important. Ensuring the quality of research is an essential part of good scientific practice and, in turn, safeguards scientific integrity. In a position paper published in 2019, the German Council for Scientific Information Infrastructures (RfII) recommends establishing the documentation of research data as a core methodological task within research practice. The RfII calls on universities and research organizations to incorporate data quality assurance and improvement into their respective research strategies. Additionally, research funding bodies can create incentives and allocate time for this purpose (RfII, 2019, p. 172). |
|---|
Data reuse, often referred to as secondary use, involves re-examining previously collected and published research datasets with the aim of gaining new insights, potentially from a different or fresh perspective. Preparing research data for reuse requires significantly more effort in terms of anonymization, preparation, and documentation than simple archiving for storage purposes. | |
|---|---|
| Related glossary entries | |
Data security encompasses all preventive physical and technical measures aimed at protecting both digital and analog data. Data security ensures data availability and safeguards the confidentiality and integrity of the data. Examples of security measures include password protection for devices and online platforms, encryption for software (e.g., emails) and hardware, firewalls, regular software updates, and secure deletion of files. | |
|---|---|
| Related glossary entries | |
Data sharing refers to the act of sharing or distributing data. According to research requirements, data should be made as open as possible and as confidential as necessary (European Commission, 2021). Particularly with regard to the reuse and handling of sensitive, personal data, it is crucial to carefully assess whether and in what form archiving and sharing data with other researchers and the public is possible and appropriate. The imperative of data sharing enjoys broad consensus within the Open Science movement but should be critically considered and weighed from a social and cultural anthropological perspective. | |
|---|---|
| Related glossary entries | |
Data storage generally refers to the process of saving data on a storage medium or device (digitalized data). Research data are unique and valuable, and should be stored securely to protect them from loss and unauthorized access. Various measures, such as regular backup routines, can help minimize potential data loss. | |
|---|---|
| Related glossary entries | |
Digital data are created through digitalization, which involves converting analog materials into formats suitable for electronic storage on digital media. Digital data offer the advantage of being easily and accurately duplicated, shared, and machine-processed. | |
|---|---|
| Related glossary entries | |
Digital methods employ computational techniques for the acquisition, processing, and analysis of data. They represent an emerging interdisciplinary field focused on developing and applying computer-based methods to analyze social, cultural, and societal phenomena. The two main branches are Digital Humanities (DH) and Computational Social Sciences (CSS). A good introduction to digital methods in qualitative research is provided by Franken (2023). |
|---|
DOI stands for Digital Object Identifier, a unique and permanent (persistent) identifier for digital objects, such as articles and contributions in scientific publications, as well as lecture publications and educational materials. A DOI must first be registered in the central database of the International DOI Foundation4 see: https://www.doi.org/. A persistent identifier refers to the object itself, not its location on the internet (unlike URLs). If the location of a digital object associated with a persistent identifier changes, the identifier remains the same; only the URL location needs to be updated or added in the identifier database. This ensures that a dataset remains permanently findable, accessible, and citable (Forschungsdaten.info, 2023). A DOI always consists of a prefix and a suffix, separated by a slash. For example, doi: 10.17169/refubium-35157.2. The suffix refubium-35157.2 refers to the publication „Zur Teilbarkeit ethnografischer Forschungsdaten. Or: How much privacy does ethnographic research need?“, which is archived in the Refubium of the Freie Universität Berlin under 17169 (see: https://refubium.fu-berlin.de/handle/fub188/35442.2). 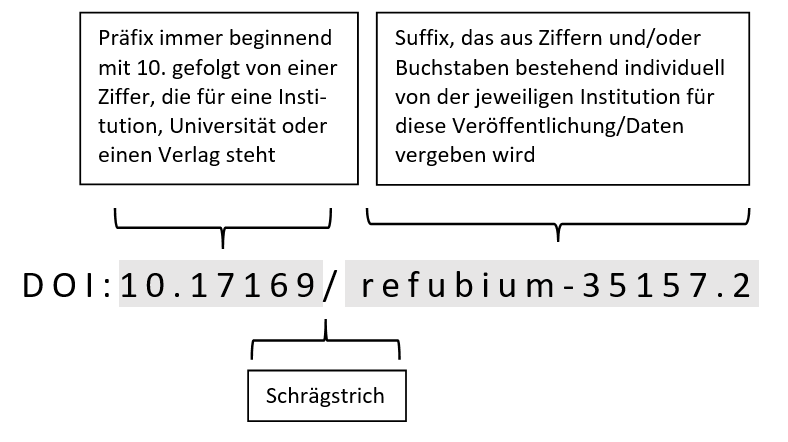 Prefix: Always starts with „10.“ followed by a number representing an institution, university, or publisher. Suffix: Consists of numbers and/or letters, assigned by the respective institution for the specific publication or dataset. DOIs can be presented in various formats, depending on the citation style:
| |
|---|---|
| Related glossary entries | |
Ethnographic field research refers to the collection of empirical data on-site, meaning within concrete social settings, as opposed to laboratory research, archival research or standardized survey studies. The typically long-term participation of ethnographers in the daily life of the group under study allows for direct observation of social practices and processes, allowing for insights into actual behavior. It is important to note that researchers are always part of the situations in the field, and their assigned and assumed social positions significantly influence their data – that is, what they are able to observe and understand. |
|---|
Data collected during ethnographic research through various methods in situ are always embedded in social interactions; that is, they arise from direct and non-anonymous exchanges between researchers and the participants in the chosen field of study. As such, these data are strongly influenced by the subjective nature of these relationships and largely constitute personal data that require special protection. | |
|---|---|
| Related glossary entries | |
The Extended Case Method (ECM) was developed in British social anthropology during the 1950s and 1960s and has become one of the standard qualitative methods in the field. It can be defined as the detailed documentation and analysis of specific events or event sequences observed in the field, from which general theoretical principles can be derived. Unlike a singular, time-limited case study, the ECM investigates the interconnectedness of multiple social events over extended periods, where the same actors are involved. This method allows for the capture of social negotiation processes. ECM data typically consist of „thick descriptions“ that contain numerous sensitive personal references, which require particularly careful protection and anonymization. |
|---|
The FAIR Principles were first developed in 2016 by the FORCE11 community (The Future of Research Communication and e-Scholarship). FORCE11 is a community of researchers, librarians, archivists, publishers, and research funders aiming to bring about change in modern scientific communication through the effective use of information technology, thereby supporting enhanced knowledge creation and dissemination. The primary goal is the transparent and open presentation of scientific processes. Accordingly, data should be made findable, accessible, interoperable, and reusable (FAIR) online. The objective is to preserve data long-term and make it available for reuse by third parties in line with Open Science and Data Sharing principles. Precise definitions by FORCE11 can be found on their website5 see: https://force11.org/info/the-fair-data-principles/. The FAIR Principles do not adequately address ethical aspects of data sharing in social science contexts, which is why they have been supplemented by the CARE Principles. | |
|---|---|
| Related glossary entries | |
The file extension specifies the type of file (document, image, video, etc.) and the format in which it is saved. The file extension also determines the default program used to open the file. It should accurately reflect the actual file type and should not be changed.
| |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Related glossary entries | |||||||||||||||||||||||
The terms „file type“ and „file format“ are often used interchangeably. A distinction is made between proprietary and open file formats. Proprietary formats usually require fee-based software to access, as they may not be compatible with other programs (e.g., PowerPoint for .ppt files or Photoshop for .psd files). In contrast, open formats such as .rtf or .png are based on standards and can be opened by many programs. Research data intended for archiving should be provided in the following formats (Biernacka et al., 2021):
| ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Synonymous glossary entries | ||||||||||||||||
| Related glossary entries | ||||||||||||||||
The file name, in conjunction with the directory path leading to the file, uniquely identifies a file. It consists of the actual name and the extension. The extension indicates the file type (text, image, video) and the format (.docx for text files, .mp4 for video files or. png for image files, and also determines the default program used to open the file. | |
|---|---|
| Synonymous glossary entries | |
| Related glossary entries | |
The terms „file type“ and „file format“ are often used interchangeably. A distinction is made between proprietary and open file formats. Proprietary formats usually require fee-based software to access, as they may not be compatible with other programs (e.g., PowerPoint for .ppt files or Photoshop for .psd files). In contrast, open formats such as .rtf or .png are based on standards and can be opened by many programs. Research data intended for archiving should be provided in the following formats (Biernacka et al., 2021):
| ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Synonymous glossary entries | ||||||||||||||||
| Related glossary entries | ||||||||||||||||
The filename uniquely identifies a file in conjunction with the directory path leading to the file. It consists of the actual name and the extension or suffix. The extension indicates the type of file (text, image, video) and the type (.docx for Word files, .mp4 for video files or .png for image files), and also determines the program in which the file is opened by default. | |
|---|---|
| Synonymous glossary entries | |
| Related glossary entries | |
Funding institutions are organizations that provide financial support for scientific research, such as foundations, associations, or other entities. Internationally, most of these institutions have established guidelines for research data management (RDM) in research projects, meaning that potential funding is tied to specific requirements and expectations for handling research data. Some of the most well-known funding institutions in German-speaking countries include the Federal Ministry of Education and Research (BMBF), the education and science ministries of the federal states, the German Research Foundation (DFG), the Volkswagen Foundation, the Austrian Science Fund (FWF), and the Swiss National Science Foundation (SNF). |
|---|
The Global Indigenous Data Alliance (GIDA) is a network of researchers, data practitioners, and political activists dedicated to ensuring that Indigenous groups:
| |
|---|---|
| Related glossary entries | |
Good scientific practice (GSP) represents a standardized code of conduct established in the guidelines of the German Research Foundation (DFG). These guidelines emphasize the ethical obligation of every researcher to act responsibly, honestly, and respectfully, also in order to strengthen public trust in research and science. They serve as a framework for guiding scientific work processes. |
|---|
A household survey is an overview study conducted through standardized surveys of a representative sample or random sample of households within a study region (see: Survey/Survey Data). In social and cultural anthropology, the terms survey, household survey, and census are often used interchangeably. | |
|---|---|
| Related glossary entries | |
Informed consent refers to the agreement of research participants to take part in a study based on the basis of comprehensive and understandable information. The design of an informed consent must address both ethical principles and data protection requirements. | |
|---|---|
| Related glossary entries | |
Interoperability is the ability of a system to work seamlessly with other systems. In interoperable systems, data can be automatically combined and exchanged with other datasets, making data machine-readable, interpretable, and comparable in a simplified and accelerated manner. Interoperability is one of the main criteria of the FAIR Principles (Forschungsdaten.info, 2023). | |
|---|---|
| Related glossary entries | |
In a license agreement or through an open license, copyright holders specify how and under what conditions their copyrighted work may be used and/or exploited by third parties. Commercial entities, such as publishers, typically enter into license agreements with the copyright holders. When these works are later reused by third parties, they must obtain permission from the rights holder (in this case, the publisher) and may need to pay a licensing fee. Open licenses, such as Creative Commons Licenses, allow free use. When openly licensed research data are used by third parties, “a contract is automatically established between the licensor and the licensee, without any need for contact between them” (TUM, 2023, p. 5). | |
|---|---|
| Related glossary entries | |
A metadata schema provides mandatory guidelines on how metadata should be structured. It specifies elements for describing research data and the required format. This standardization and regulation of metadata improve machine readability, comparability, and facilitate automated data usage and capture. | |
|---|---|
| Related glossary entries | |
Metadata standards enable the uniform description of similar data using metadata. They establish terms, meanings, structure, and format as standards for specific disciplines, for example. Metadata standards enhance data discoverability and support interoperability between applications, thereby facilitating data exchange, comparison, and linkage across datasets6(Have a look at the following example: https://www.dublincore.org/specifications/dublin-core/dcmi-terms/).. | |
|---|---|
| Related glossary entries | |
Metadata are descriptions of research data (data about data) and provide content-related and structured information about the research context, methodological and analytical procedures, as well as the research team that generated the data. They can be categorized into bibliographic, administrative, procedural, and descriptive metadata and are typically created using templates, ReadMe files, or data curation profiles. Metadata are published alongside the research data themselves and are essential in online repositories and research data centers, where they enable third parties to understand and contextualize datasets. Metadata also enhances the findability and machine-readability of data, making them a key component of the FAIR Principles and good scientific practice. | |
|---|---|
| Related glossary entries | |
Open Access refers to the free, costless, unrestricted, and barrier-free access to scientific knowledge and materials. For third parties to reuse these materials legally, the creators must grant usage rights through a licensing agreement. Free CC licenses, for example, specify exactly how data and materials may be reused. There are two primary paths for publishing scientific content: the golden path, which involves first-time Open Access publication of scientific texts, often in monographs or similar formats, and the green path, which allows for secondary publication on institutional repositories or the authors‘ own websites (Open Access Network, 2023). | |
|---|---|
| Related glossary entries | |
Open data are data that are openly and freely accessible online and may be reused by third parties without restriction. This requires that they are provided with an open license (Opendefinition, 2023). | |
|---|---|
| Related glossary entries | |
Since the early 2000s, the Open Science movement has advocated for an open and transparent approach to science in which all stages of the scientific knowledge process are made openly accessible online. This means that not only the final results of research, such as monographs or articles, are shared publicly, but also materials that accompanied the research process, such as lab notebooks, research data, software used, and research reports. This approach aims to promote public participation in science and knowledge, engaging interested audiences. It also seeks to encourage creativity, innovation, and new collaborations, while enabling the verification of findings in terms of quality, accuracy, and authenticity – a process intended to democratize research. Components of Open Science include Open Access and Open Data, which provide the infrastructure for sharing interim research results. | |
|---|---|
| Related glossary entries | |
“Open Science encompasses strategies and practices aimed at making all components of the scientific process openly accessible and reusable on the internet. This approach is intended to open up new possibilities for science, society, and industry in handling scientific knowledge” (AG Open Science, 2014, translation by Saskia Köbschall). Under the terms Open Access, Open Data, Open Source, and others – all of which fall under the umbrella of Open Science – scientists are increasingly making publications, research data, and code freely accessible online. | |
|---|---|
| Related glossary entries | |
An attitude of methodological openness is essential in ethnographic research to adapt to the dynamics of social processes and respond to unforeseen events in the field. A fixed, unchangeable set of research methods does not meet these requirements. Furthermore, ethnographic research is also characterized by openness toward research materials after data collection; this approach encourages the continuous establishment of new theoretical perspectives on the material in order to allow for constructive and multi-layered interpretations. |
|---|
An example of a standardized identifier for uniquely identifying individuals is the ORCID (Open Researcher and Contributor ID). ORCID is an internationally recognized persistent identifier that allows researchers to be uniquely identified. The ID can be used by researchers for their scientific publications permanently and independently of any institution. It consists of 16 digits, grouped in four sets of four (e.g., 0000-0002-2792-2625). ORCID IDs are widely established in workflows at numerous publishers, universities, and research-related institutions and are often integrated into the peer-review process for journal articles7 An ORCID can be created free of charge at https://orcid.org/.. | |
|---|---|
| Related glossary entries | |
Personal data includes: “any information relating to an identified or identifiable natural person (data subject); an identifiable natural person is one who can be identified, directly or indirectly, in particular by reference to an identifier such as a name, an identification number, location data, an online identifier, or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural, or social identity of that natural person(…)” (EU GDPR Article 4 No. 1, 2016; BDSG §46 para. 1, 2018; BlnDSG §31, 2020). | |
|---|---|
| Related glossary entries | |
A Persistent Identifier (PID) is a permanent digital code directly associated with a digital resource, such as a dataset, scholarly article, or other publication, making it permanently identifiable and findable. Unlike other serial identifiers (e.g., URLs), a Persistent Identifier refers to the object itself rather than its location on the internet. If the location of a digital object associated with a Persistent Identifier changes, the identifier remains the same; only the URL location in the identifier database needs to be updated or supplemented. This ensures that a dataset remains permanently findable, accessible, and citable (Forschungsdaten.info, 2023). PIDs play a central role in the FAIR (Findable, Accessible, Interoperable, Reusable) use of research data and are explicitly mentioned in the FAIR Principles. Research data should be accessible, interoperable, and reusable, but they must first be discoverable. Globally unique and persistent identifiers are essential for identifying published resources and providing machine-readable metadata. PIDs are not only assigned to datasets and publications but are relevant for all aspects of the research data lifecycle, including the researchers themselves, as well as organizations and funding institutions. | |
|---|---|
| Related glossary entries | |
Primary data are data collected directly in relation to a research subject „in the field.“ In field research, this may include field observations and corresponding notes in field journals, interview transcripts, conversation protocols, as well as quantitative data collected through questionnaires, and data created with and by research participants, such as photographs, films, etc. In contrast, secondary data are created through reuse, meaning an additional processing step (e.g., statistical analysis) of the primary data. Secondary data no longer reflect the original form of the primary data. | |
|---|---|
| Related glossary entries | |
The term „processing“ is defined as „any operation or set of operations which is performed on personal data or on sets of personal data, whether or not by automated means, such as collection, recording, organisation, structuring, storage, adaptation or alteration, retrieval, consultation, use, disclosure by transmission, dissemination or otherwise making available, alignment or combination, restriction, erasure or destruction;“ (BlnDSG §31, 2020; EU GDPR Article 4 No. 2, 2016). Processing therefore refers to any form of working with personal data, from collection to erasure. | |
|---|---|
| Related glossary entries | |
Proprietary file formats are file formats that cannot be opened or read by third parties, or only with difficulty, because they are protected by license or patent. In most cases, special (paid) software is required for this (Wikipedia, 2023). Examples include the Word format.docx or the Adobe Photoshop format.psd. |
|---|
Pseudonymization is „the processing of personal data in such a way that the data can no longer be attributed to a specific data subject without the use of additional information, provided that such additional information is kept separately and is subject to technical and organizational measures to ensure that the personal data cannot be attributed to an identified or identifiable natural person“ (BlnDSG §31, 2020; EU GDPR Article 4 No. 5, 2016). | |
|---|---|
| Related glossary entries | |
The processing of personal data is only permissible for specified and clear purposes. These purposes should ideally be determined as precisely as possible before data collection and, where feasible, documented in a consent form as part of the research project. Further processing steps are tied to this initial purpose. If the purposes change or expand during the research project – for instance, if new research questions arise during data analysis – additional consent from the affected individuals may need to be obtained. Data must be deleted once the purpose has been fulfilled. Personal data may not be stored in an identifiable form for longer than necessary for the intended purposes. The scope of personal data processing must be proportionate to the purpose, meaning only the minimum amount of personal data necessary and feasible should be collected and processed (BlnDSG §32, 2018). |
|---|
ReadMe files in the context of systems or projects ReadMe files in the context of research data | |
|---|---|
| Related glossary entries | |
Related rights are ancillary rights under copyright law. They do not protect the work itself but rather the artistic or scientific performance of individuals or an investment made. This applies particularly to the creation of databases or the production of films. An artistic or scientific performance could include a theater performance, a translation of a work, or the creation of an image, such as a photograph or an X-ray. The German Act on Copyright and Related Rights provides for the following related rights (§§ 70-94) (UrhG, 2021):
| |
|---|---|
| Related glossary entries | |
A repository is a storage location for academic documents. In online repositories, publications are digitally stored, managed, and assigned persistent identifiers. Cataloging facilitates the search and use of publications and author information. In most cases, documents in online repositories are openly and freely accessible (Open Access). |
|---|
The Research Data Centre (RDC) Qualiservice provides qualitative social science data for scientific reuse. Accredited in 2019 by the German Council for Social and Economic Data (RatSWD), it adheres to their quality assurance criteria. In addition to data reuse, researchers have the option to share and organize their own research data, with the Qualiservice team offering advisory support. Qualiservice is committed to the DFG guidelines for ensuring good scientific practice and also adheres to the FAIR Guiding Principles for Scientific Data Management and Stewardship as well as the OECD Principles and Guidelines for Access to Research Data from Public Funding8For further informationen see also: https://www.qualiservice.org/en/. |
|---|
The research data lifecycle model represents all the phases that research data can go through, from the point of collection to their reuse. These phases are linked to specific tasks and may vary (Forschungsdaten.info, 2023). Generally, the research data lifecycle includes the following stages:
|
|---|
Research data management is aimed at handling research data in a responsible and well-considered manner. The idea is to carefully organize, maintain and process research data using specific measures and strategies. The goal is to store data long-term and make it accessible and reusable by others, in line with good scientific practice. This enables easier verification of scientific findings, secures evidence, and allows for further evaluations and analyses of the data. |
|---|
„Data that are a) created through scientific processes/research (e.g. through measurements, surveys, source work), b) the basis for scientific research (e.g. digital artefacts), or c) documenting the results of research, can be called research data. |
|---|
Research ethics addresses the relationship between researchers, the research field, and the subjects/participants of the research. This relationship is critically examined against the backdrop of vulnerabilities and power asymmetries created by the research process (Unger, Narimani & M’Bayo, 2014, p.1-2). Due to the processual and open-ended nature of ethnographic research, ethical questions arise throughout the research process in various ways, depending on the research context and methods. However, research ethics does not end with leaving the field; it also encompasses issues related to data archiving, data protection, and sharing research data with participants (see, for example, ethics guidelines by the DGSKA or the position paper on archiving, provision, and reuse of research data by the dgv). Key concepts associated with research ethics include: informed consent, voluntary participation, and assessing and minimizing risks and dangers to those involved. |
|---|
The right to one’s own image means that every person can decide whether and where their image is published. According to §22 of the German Art Copyright Act (Kunsturhebergesetz), the distribution and publication of a photograph featuring identifiable individuals requires the consent of the depicted person, whether in print media or online 9For further information see: https://www.gesetze-im-internet.de/kunsturhg/__22.html. |
|---|
Secondary data are data derived from primary data through further processing steps (e.g., statistical analyses) and then serve as a basis for additional evaluations. Secondary data are derived from primary data but no longer reflect the original form of the primary data. In social and cultural anthropology, this distinction between primary and secondary data, which is significant in statistics, is of little relevance. | |
|---|---|
| Related glossary entries | |
Securely deleting digital research data involves more than simply moving files to the digital trash bin, as this only deletes the file references, not the data itself. To ensure data is completely erased, special data shredding programs should be used, or data should be overwritten with meaningless data, or the storage medium should be physically destroyed (BSI, 2023b). | |
|---|---|
| Related glossary entries | |
Research data, especially sensitive data, should be protected from unauthorized access. Secure, meaning strong and unique, passwords that require significant time and computational power to decipher are a key component of this protection. Generally, the higher the complexity of the password, the more secure it is. Tips for password creation:
| |
|---|---|
| Related glossary entries | |
Within the category of personal data, there is a subset known as special categories of personal data. Their definition originates from Article 9(1) of the EU GDPR (2016), which states that these include information about the data subject’s:
This category also includes genetic and biometric data (e.g., fingerprints) used to identify a natural person. Under the General Data Protection Regulation (GDPR), these types of information are considered „sensitive“ because their collection, processing, or use may pose significant risks to the data subjects. Therefore, they are subject to special requirements and processing conditions. As a general rule, consent from the data subject must be obtained for the processing of personal data. Exceptions apply if the data have been made public by the data subject or if there is significant public interest (EU GDPR Article 9(2), 2016). Ethnographic research projects often involve the collection of personal data, which is considered sensitive under the GDPR. | |
|---|---|
| Synonymous glossary entries | |
| Related glossary entries | |
Within personal data, there is a subset known as special categories of personal data. This definition originates from Article 9(1) of the EU GDPR (2016), which states that this includes information on:
It also includes genetic and biometric data (e.g. fingerprints) for identifying a natural person. According to the General Data Protection Regulation, this information is considered “sensitive” because its collection, processing or use may pose significant risks to the data subjects. They are therefore subject to special obligations and processing conditions. As a general rule, the consent of the data subjects must be obtained for the processing of personal data. Exceptions apply if the data has been made public by the data subject themselves or if there is a substantial public interest (EU GDPR Article 9 (2), 2016). Personal data, which is considered highly sensitive according to the General Data Protection Regulation, regularly arises in ethnographic research projects. | |
|---|---|
| Synonymous glossary entries | |
| Related glossary entries | |
The Specialized Information Service for Social and Cultural Anthropology (FID SKA) provides members of the German Society for Empirical Cultural Studies and the German Society for Social and Cultural Anthropology, as well as other interested researchers to a limited extent, with selected online resources for research. |
|---|
Supplements to scientific publications are materials and research data published alongside a scientific article, as journal articles typically present only a summarized form of data analysis and research findings. Supplements may include detailed explanations, the datasets themselves, or additional information that clarifies the context of the collected data, thereby enhancing the transparency and reproducibility of materials and research data. |
|---|
In the social sciences, a survey refers to standardized, quantitative overview studies that provides information on specific groups or observational units, such as households, family structures, age groups (youth, retirees, workers, etc.), or individual companies and organizations. Survey data are usually collected through questionnaires or structured interviews. These data represent statistical microdata, allowing for the investigation of relationships and characteristics at the individual level. Surveys are standard methods in quantitative social research and are also employed in social and cultural anthropology to gather general information on social parameters, such as household compositions, economic conditions, or age structures within a population. | |
|---|---|
| Related glossary entries | |
A time allocation study systematically measures the amount of time individuals spend on specific tasks and activities. These studies examine how people budget their time in various social and cultural contexts. For example, they explore how the division of labor in productive and reproductive activities is organized across genders and generations: How much time per day do mothers, fathers, older siblings, grandparents, and others spend caring for young children? How much time is allocated by whom to economic activities, caregiving tasks, or neighborhood interactions? Various methods are used to measure time budgeting, generating quantitative and replicable datasets. |
|---|
Two-factor authentication (2FA) supplements password protection by requiring a one-time code, delivered via SMS, smartphone app, or hardware token. This method significantly enhances security, as access to the smartphone or similar device is also necessary in order to gain access to the protected data. | |
|---|---|
| Related glossary entries | |
Versioning refers to the documentation of all changes made to research data during the work process. It is recommended to save a new version of the data for each adjustment to ensure traceability. This can be done manually using versioning schemes (e.g., numbering: Version 1.3.2) or by using versioning software like Git. Versioning occurs during the research process itself but can also be applied retrospectively to already published research data to provide third parties with the correct version for reuse. | |
|---|---|
| Related glossary entries | |